Sharing experiment data and materials is a key component of open science and is becoming increasingly common (Kidwell et al. 2016). But some in Visualization and HCI have expressed concern that this practice may not be compatible with anonymous submissions. Not true! Open data and open materials can easily be shared anonymously.
Why you should
- In 2018, it’s sketchy not to. Hiding details of your work makes it seem like you’re up to something nefarious.
- It can save you a review cycle. Sometimes when a reviewer has concerns about a submission’s results, they can check the submitted data to see where the problem lies. If they find it’s only minor reporting issue, you could be spared a rejection.
- Safe Keeping. Using an archive with preservation funding means that your work is safe from the many mishaps that could occur in the years or decades after collecting data.
- More citations. If others follow up on your work by reusing the experiment materials or incorporating the data into a new analysis, your article gets more citations. Increase your impact factor by facilitating followups.
- Pay it forward. Posting your own data and materials can help establish a community norm in which everyone does the same. Down the road, that could help you incorporate someone’s data into your meta-analysis or reuse their experiment materials.
How to post your data and materials
1) Make an Open Science Framework account. It takes seconds at http://osf.io. (Note on email address: I’ve never gotten any spam from them)
2) Make a new project. Give it a name, add collaborators, and fill in other details. You can update everything later, too.
3) Upload your content. Encapsulate each experiment’s materials, data, and (if possible) analysis in its own subdirectory. Also, put a current draft of the paper at the root.
Post all the materials for each experiment, including the code, parameters, and any special running instructions. Think about what someone 5, 10, or 50 years from now would need.
For experiment data, make sure to also post a dictionary that describes every field. Posting your analysis script along with the data is a helpful addition that can improve replicability and help justify your results.
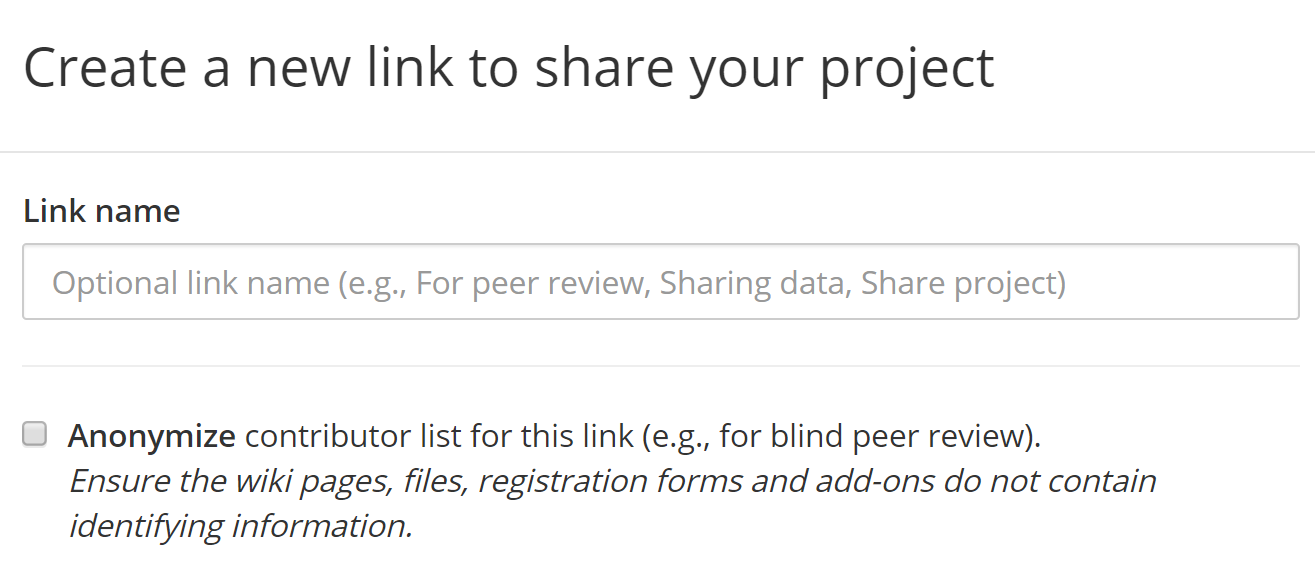
4) If anonymity is a concern, make an anonymous view-only link. With your project open, go to Settings (top-right) -> View-Only Links -> Add. Then check “Anonymize”. Then you can share that URL.
5) Add the link to your abstract! Don’t bury it deep in the paper or all the way at the end. Put it on the first page! (Note: the url is much shorter once you make the project public, so don’t worry about the length)
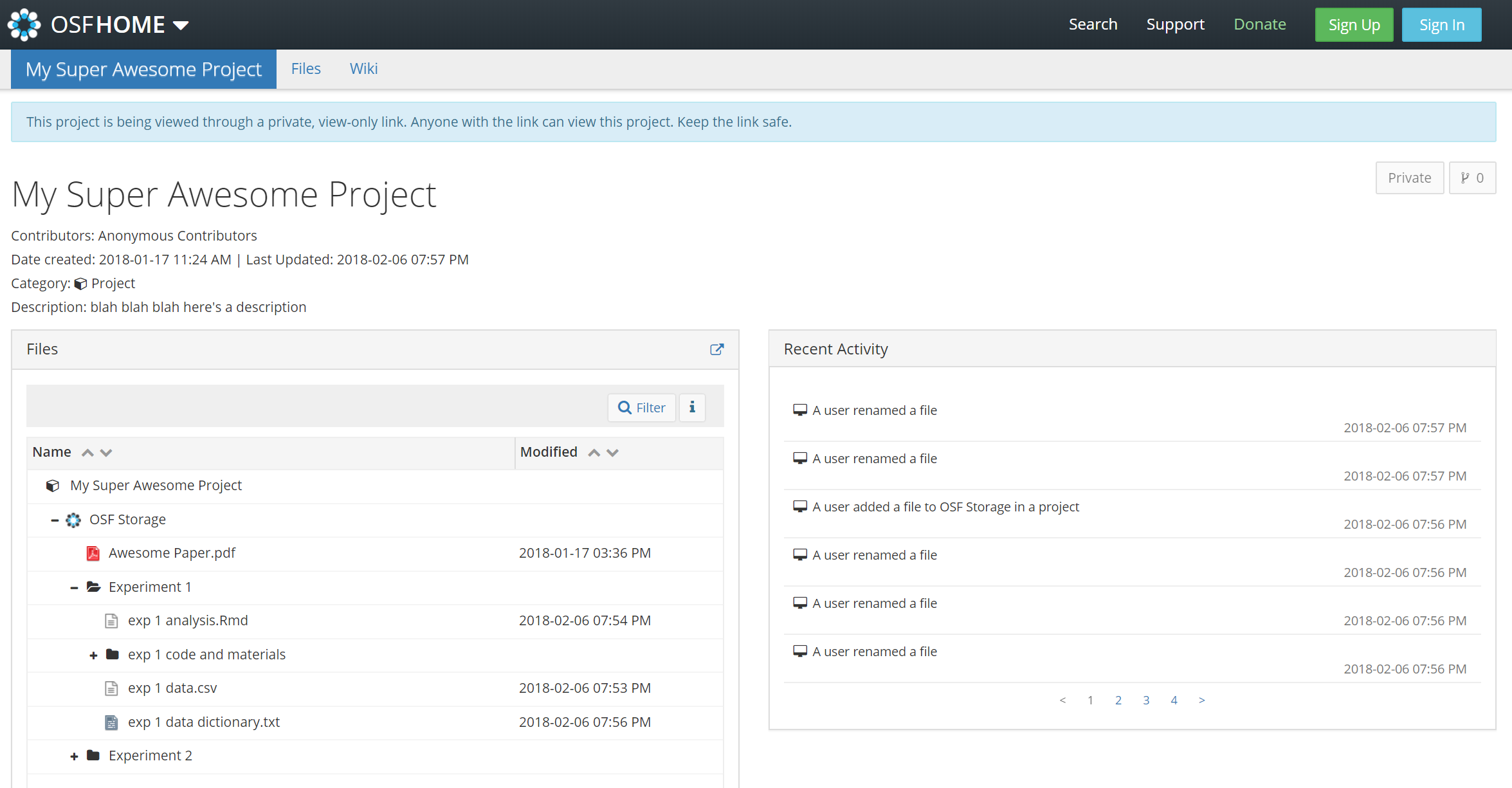
6) Make it public. After accepted (or before!), make the project public. That’ll give you a shorter URL and will reveal all the collaborator names.
What to share
- Experiment results – Share raw data of each trial, rather than aggregated data for each subject or condition. Also include the subject’s response, not just whether it was correct. The aim should be to provide data that has not gone through any analysis. More info
- Experiment materials – Share everything needed for someone to rerun your experiment just as you ran it. That includes code, stimulus information, instructions, etc. More info
- Analysis – It’s less critical but suggested to share how you derived the results and figures in the paper from the data.
Don’t worry about the IRB
For performance experiments that have IRB approval, there’s rarely any risk in releasing the data. Just make sure that the data doesn’t contain any personal or identifying information (especially mTurk IDs, text fields, IPs, or any images/audio of the subjects). When in doubt, drop fields that are potentially identifying but not critical to the results.
Great blog! The anonymous, view-only links that we put on the OSF are a great feature. My only small quibble is with the IRB comment near the end. I suspect that criteria differ by location, but my understanding is that any research using data collected from people requires IRB review, even if it results in exempt or expedited review. My recommendation is to check with your local IRB. These pages have some recommended language for IRB reviews and informed consent: https://osf.io/g4jfv/wiki and https://osf.io/9d5hr/
Thanks David. I’ve clarified that section a bit. Something I’ve encountered multiple times is people responding to data requests with “I need to ask my IRB”. If the experiment tests some simple performance property (like speed or accuracy) and doesn’t include identifying info, I’m not sure why the IRB would have any concern.
I’ll just add that in all of my previous IRB applications, I have stated that the data would never be shared outside the research group and my IRB even wants to know which computers the data will be stored on, how those computers are secured, whether I sync that machine with a cloud storage service, and so on. This is in a field that generates “typical” pyschological data, nothing particularly invasive. i would suspect that posting my data online for those studies could get me in some real trouble with the IRB.
Hi Jacob. Everyone releases data in aggregate form in the results section of a paper. If you graph or mention a specific outlier, you releasing a subset of the data without aggregated. Since the IRB mostly applies to data that will be collected for publishable research, they shouldn’t even let you claim that no data will be released.
More importantly, I don’t know of any case where the IRB caused any trouble following the release of anonymous data.